|
|
|
|
Sparta is a lightweight Java XML package that includes an XML parser, a DOM, and an XPath interpreter. The code-size is small, the parser is fast, the object memory size is small, and the DOM API is clean and simple. Thermopylae is a wrapper around Sparta that allows it to be used as a drop-in replacement for Xerces. It presents a W3C-standard parser and DOM. Sparta was originally written in Hewlett-Packard Labs to support a project creating an infrastructure for building agile applications that distribute themselves throughout the global Internet and aggregate ensembles of local appliances. Current StatusWe have transferring the source code from our internal HP Labs CVS to sourceforge and the documentation from our internal wiki. The next step is to transfer our JUnit testing environment too. Quick StartDownload Sparta. See Sparta Example for a some Java code that uses Sparta and Porting to Sparta to see how to port from standard DOM code.
General Features
The SpartaXPath expression languages is a subset of the full Xpath grammar.[2]. It supports only the abbreviated syntax[3], which in practice is what most people use. The XPath handling is integrated into the DOM via xpathSelect* methods of the com.hp.hpl.sparta.Document and com.hp.hpl.sparta.Element classes. The toString method of the DOM
nodes returns the concatenation of all text nodes hierarchically under the given
node. This gives convenient functionality similar to one provided in XSLT.
Thus if a document contains the XML
"
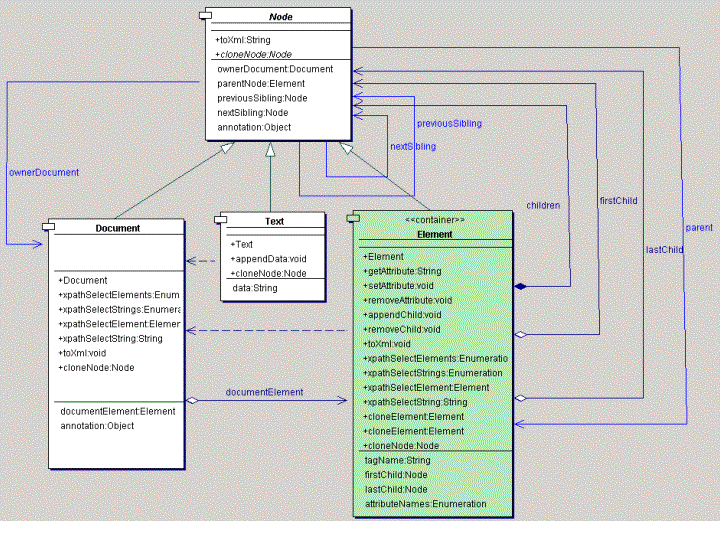
Design and Implementation
XML Parser and DOMCvs:sparta/java/com/hp/hpl/agile/sparta
XPathThe XPath code is split up into two parts:
PerformanceBelow are some performance measures comparing Sparta and Thermopylae to two other popular Java XML parsers: Xerces and Crimson. Conclusion: Sparta or Thermopylae can parse XML more than twice as fast as the Crimson parser and more than five times faster than the popular Xerces parser. Based on the serialization experiments access to the Sparta DOM is 44% faster than access to the Crimson DOM and more than three times faster than access to the Xerces DOM. Access to the Thermopylae DOM is slightly slower than access to the Crimson DOM. Additionally when we increase the size of the XML to be parsed the Xerces parser runs out of memory. Parsing from bytes to DOM:
Serialization from DOM to String:
Details: The times measured are wall-clock time on a Pentium-III HP Omnibook 6000 laptop. The time does not include reading from file. The XML parsed was 43,000 lines XML from the XMLConf test suite[4] that did not have deliberate syntax and well-formedness errors. Each result above is the mean of at least five runs.
(Naming note: The Greek city-state of Sparta was a lean-and-mean rival to the King Xerces of the Persian Empire. Xerces is also the name of the most common full XML parser and DOM.[5] Thermopylae is the battle in which Xerces defeated the Spartans.)
|
|
|